Tutorial 3: Confidence intervals and bootstrapping
Contents
![]()

Tutorial 3: Confidence intervals and bootstrapping¶
Week 1, Day 2: Model Fitting
By Neuromatch Academy
Content creators: Pierre-Étienne Fiquet, Anqi Wu, Alex Hyafil with help from Byron Galbraith
Content reviewers: Lina Teichmann, Saeed Salehi, Patrick Mineault, Ella Batty, Michael Waskom
Production editors: Spiros Chavlis
Tutorial Objectives¶
Estimated timing of tutorial: 23 minutes
This is Tutorial 3 of a series on fitting models to data. We start with simple linear regression, using least squares optimization (Tutorial 1) and Maximum Likelihood Estimation (Tutorial 2). We will use bootstrapping to build confidence intervals around the inferred linear model parameters (Tutorial 3). We’ll finish our exploration of regression models by generalizing to multiple linear regression and polynomial regression (Tutorial 4). We end by learning how to choose between these various models. We discuss the bias-variance trade-off (Tutorial 5) and Cross Validation for model selection (Tutorial 6).
In this tutorial, we will discuss how to gauge how good our estimated model parameters are.
Learn how to use bootstrapping to generate new sample datasets
Estimate our model parameter on these new sample datasets
Quantify the variance of our estimate using confidence intervals
Setup¶
⚠ Experimental LLM-enhanced tutorial ⚠
This notebook includes Neuromatch’s experimental Chatify 🤖 functionality. The Chatify notebook extension adds support for a large language model-based “coding tutor” to the materials. The tutor provides automatically generated text to help explain any code cell in this notebook.
Note that using Chatify may cause breaking changes and/or provide incorrect or misleading information. If you wish to proceed by installing and enabling the Chatify extension, you should run the next two code blocks (hidden by default). If you do not want to use this experimental version of the Neuromatch materials, please use the stable materials instead.
To use the Chatify helper, insert the %%explain magic command at the start of any code cell and then run it (shift + enter) to access an interface for receiving LLM-based assitance. You can then select different options from the dropdown menus depending on what sort of assitance you want. To disable Chatify and run the code block as usual, simply delete the %%explain command and re-run the cell.
Note that, by default, all of Chatify’s responses are generated locally. This often takes several minutes per response. Once you click the “Submit request” button, just be patient– stuff is happening even if you can’t see it right away!
Thanks for giving Chatify a try! Love it? Hate it? Either way, we’d love to hear from you about your Chatify experience! Please consider filling out our brief survey to provide feedback and help us make Chatify more awesome!
Run the next two cells to install and configure Chatify…
%pip install -q davos
import davos
davos.config.suppress_stdout = True
Note: you may need to restart the kernel to use updated packages.
smuggle chatify # pip: git+https://github.com/ContextLab/chatify.git
%load_ext chatify
Downloading and initializing model; this may take a few minutes...
llama.cpp: loading model from /home/runner/.cache/huggingface/hub/models--TheBloke--Llama-2-7B-Chat-GGML/snapshots/501a3c8182cd256a859888fff4e838c049d5d7f6/llama-2-7b-chat.ggmlv3.q5_1.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 9 (mostly Q5_1)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 6390.60 MB (+ 1026.00 MB per state)
llama_new_context_with_model: kv self size = 256.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
Install and import feedback gadget¶
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W1D2_T3"
# Imports
import numpy as np
import matplotlib.pyplot as plt
Figure Settings¶
# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
Plotting Functions¶
# @title Plotting Functions
def plot_original_and_resample(x, y, x_, y_):
""" Plot the original sample and the resampled points from this sample.
Args:
x (ndarray): An array of shape (samples,) that contains the input values.
y (ndarray): An array of shape (samples,) that contains the corresponding
measurement values to the inputs.
x_ (ndarray): An array of shape (samples,) with a subset of input values from x
y_ (ndarray): An array of shape (samples,) with a the corresponding subset
of measurement values as x_ from y
"""
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
ax1.scatter(x, y)
ax1.set(title='Original', xlabel='x', ylabel='y')
ax2.scatter(x_, y_, color='c')
ax2.set(title='Resampled', xlabel='x', ylabel='y',
xlim=ax1.get_xlim(), ylim=ax1.get_ylim());
Introduction¶
Up to this point we have been finding ways to estimate model parameters to fit some observed data. Our approach has been to optimize some criterion, either minimize the mean squared error or maximize the likelihood while using the entire dataset. How good is our estimate really? How confident are we that it will generalize to describe new data we haven’t seen yet?
One solution to this is to just collect more data and check the MSE on this new dataset with the previously estimated parameters. However this is not always feasible and still leaves open the question of how quantifiably confident we are in the accuracy of our model.
In Section 1, we will explore how to implement bootstrapping. In Section 2, we will build confidence intervals of our estimates using the bootstrapping method.
Video 1: Confidence Intervals & Bootstrapping¶
Submit your feedback¶
# @title Submit your feedback
content_review(f"{feedback_prefix}_Confidence_Intervals_and_Bootstrapping_Video")
Section 1: Bootstrapping¶
Estimated timing to here from start of tutorial: 7 min
Bootstrapping is a widely applicable method to assess confidence/uncertainty about estimated parameters, it was originally proposed by Bradley Efron. The idea is to generate many new synthetic datasets from the initial true dataset by randomly sampling from it, then finding estimators for each one of these new datasets, and finally looking at the distribution of all these estimators to quantify our confidence.
Note that each new resampled datasets will be the same size as our original one, with the new data points sampled with replacement i.e. we can repeat the same data point multiple times. Also note that in practice we need a lot of resampled datasets, here we use 2000.
To explore this idea, we will start again with our noisy samples along the line \(y_i = 1.2x_i + \epsilon_i\), but this time, we only use half the data points as last time (15 instead of 30).
¶
Execute this cell to simulate some data
#@title
#@markdown Execute this cell to simulate some data
# setting a fixed seed to our random number generator ensures we will always
# get the same psuedorandom number sequence
np.random.seed(121)
# Let's set some parameters
theta = 1.2
n_samples = 15
# Draw x and then calculate y
x = 10 * np.random.rand(n_samples) # sample from a uniform distribution over [0,10)
noise = np.random.randn(n_samples) # sample from a standard normal distribution
y = theta * x + noise
fig, ax = plt.subplots()
ax.scatter(x, y) # produces a scatter plot
ax.set(xlabel='x', ylabel='y');
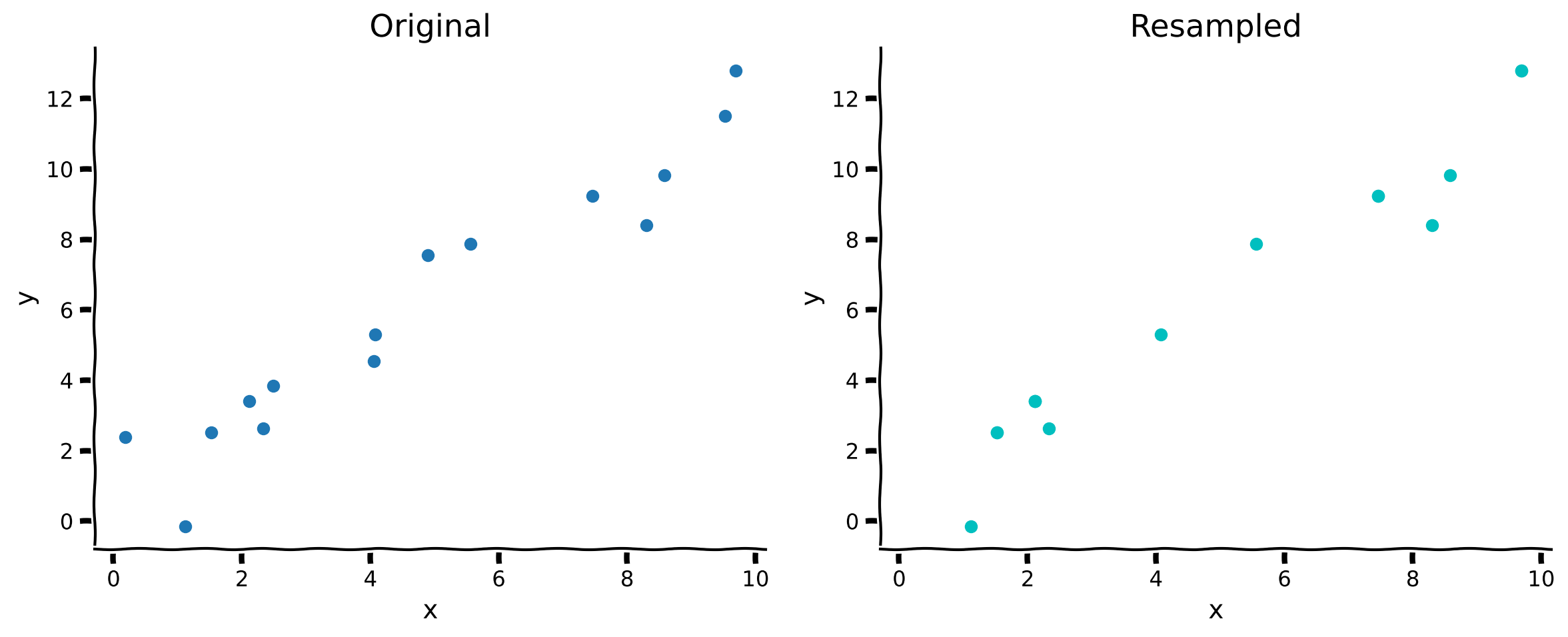
Coding Exercise 1: Resample Dataset with Replacement¶
In this exercise you will implement a method to resample a dataset with replacement. The method accepts \(\mathbf{x}\) and \(\mathbf{y}\) arrays. It should return a new set of \(\mathbf{x}'\) and \(\mathbf{y}'\) arrays that are created by randomly sampling from the originals.
We will then compare the original dataset to a resampled dataset.
Hint: The numpy.random.choice method would be useful here.
def resample_with_replacement(x, y):
"""Resample data points with replacement from the dataset of `x` inputs and
`y` measurements.
Args:
x (ndarray): An array of shape (samples,) that contains the input values.
y (ndarray): An array of shape (samples,) that contains the corresponding
measurement values to the inputs.
Returns:
ndarray, ndarray: The newly resampled `x` and `y` data points.
"""
#######################################################
## TODO for students: resample dataset with replacement
# Fill out function and remove
raise NotImplementedError("Student exercise: resample dataset with replacement")
#######################################################
# Get array of indices for resampled points
sample_idx = ...
# Sample from x and y according to sample_idx
x_ = ...
y_ = ...
return x_, y_
x_, y_ = resample_with_replacement(x, y)
plot_original_and_resample(x, y, x_, y_)
Example output:
Submit your feedback¶
# @title Submit your feedback
content_review(f"{feedback_prefix}_Resample_dataset_with_replacement_Exercise")
In the resampled plot on the right, the actual number of points is the same, but some have been repeated so they only display once.
Now that we have a way to resample the data, we can use that in the full bootstrapping process.
Coding Exercise 2: Bootstrap Estimates¶
In this exercise you will implement a method to run the bootstrap process of generating a set of \(\hat\theta\) values from a dataset of inputs (\(\mathbf{x}\)) and measurements (\(\mathbf{y}\)). You should use resample_with_replacement here, and you may also invoke the helper function solve_normal_eqn from Tutorial 1 to produce the MSE-based estimator.
We will then use this function to look at the theta_hat from different samples.
Execute this cell for helper function solve_normal_eqn
# @markdown Execute this cell for helper function `solve_normal_eqn`
def solve_normal_eqn(x, y):
"""Solve the normal equations to produce the value of theta_hat that minimizes
MSE.
Args:
x (ndarray): An array of shape (samples,) that contains the input values.
y (ndarray): An array of shape (samples,) that contains the corresponding
measurement values to the inputs.
thata_hat (float): An estimate of the slope parameter.
Returns:
float: the value for theta_hat arrived from minimizing MSE
"""
theta_hat = (x.T @ y) / (x.T @ x)
return theta_hat
def bootstrap_estimates(x, y, n=2000):
"""Generate a set of theta_hat estimates using the bootstrap method.
Args:
x (ndarray): An array of shape (samples,) that contains the input values.
y (ndarray): An array of shape (samples,) that contains the corresponding
measurement values to the inputs.
n (int): The number of estimates to compute
Returns:
ndarray: An array of estimated parameters with size (n,)
"""
theta_hats = np.zeros(n)
##############################################################################
## TODO for students: implement bootstrap estimation
# Fill out function and remove
raise NotImplementedError("Student exercise: implement bootstrap estimation")
##############################################################################
# Loop over number of estimates
for i in range(n):
# Resample x and y
x_, y_ = ...
# Compute theta_hat for this sample
theta_hats[i] = ...
return theta_hats
# Set random seed
np.random.seed(123)
# Get bootstrap estimates
theta_hats = bootstrap_estimates(x, y, n=2000)
print(theta_hats[0:5])
You should see [1.27550888 1.17317819 1.18198819 1.25329255 1.20714664] as the first five estimates.
Submit your feedback¶
# @title Submit your feedback
content_review(f"{feedback_prefix}_Bootsrap_Estimates_Exercise")
Now that we have our bootstrap estimates, we can visualize all the potential models (models computed with different resampling) together to see how distributed they are.
¶
Execute this cell to visualize all potential models
#@title
#@markdown Execute this cell to visualize all potential models
fig, ax = plt.subplots()
# For each theta_hat, plot model
theta_hats = bootstrap_estimates(x, y, n=2000)
for i, theta_hat in enumerate(theta_hats):
y_hat = theta_hat * x
ax.plot(x, y_hat, c='r', alpha=0.01, label='Resampled Fits' if i==0 else '')
# Plot observed data
ax.scatter(x, y, label='Observed')
# Plot true fit data
y_true = theta * x
ax.plot(x, y_true, 'g', linewidth=2, label='True Model')
ax.set(
title='Bootstrapped Slope Estimation',
xlabel='x',
ylabel='y'
)
# Change legend line alpha property
handles, labels = ax.get_legend_handles_labels()
handles[0].set_alpha(1)
ax.legend();
This looks pretty good! The bootstrapped estimates spread around the true model, as we would have hoped. Note that here we have the luxury to know the ground truth value for \(\theta\), but in applications we are trying to guess it from data. Therefore, assessing the quality of estimates based on finite data is a task of fundamental importance in data analysis.
Section 2: Confidence Intervals¶
Estimated timing to here from start of tutorial: 17 min
Let us now quantify how uncertain our estimated slope is. We do so by computing confidence intervals (CIs) from our bootstrapped estimates. The most direct approach is to compute percentiles from the empirical distribution of bootstrapped estimates. Note that this is widely applicable as we are not assuming that this empirical distribution is Gaussian.
¶
Execute this cell to plot bootstrapped CI
#@title
#@markdown Execute this cell to plot bootstrapped CI
theta_hats = bootstrap_estimates(x, y, n=2000)
print(f"mean = {np.mean(theta_hats):.2f}, std = {np.std(theta_hats):.2f}")
fig, ax = plt.subplots()
ax.hist(theta_hats, bins=20, facecolor='C1', alpha=0.75)
ax.axvline(theta, c='g', label=r'True $\theta$')
ax.axvline(np.percentile(theta_hats, 50), color='r', label='Median')
ax.axvline(np.percentile(theta_hats, 2.5), color='b', label='95% CI')
ax.axvline(np.percentile(theta_hats, 97.5), color='b')
ax.legend()
ax.set(
title='Bootstrapped Confidence Interval',
xlabel=r'$\hat{{\theta}}$',
ylabel='count',
xlim=[1.0, 1.5]
);
Looking at the distribution of bootstrapped \(\hat{\theta}\) values, we see that the true \(\theta\) falls well within the 95% confidence interval, which is reassuring. We also see that the value \(\theta = 1\) does not fall within the confidence interval. From this we would reject the hypothesis that the slope was 1.
Summary¶
Estimated timing of tutorial: 23 minutes
Bootstrapping is a resampling procedure that allows to build confidence intervals around inferred parameter values
it is a widely applicable and very practical method that relies on computational power and pseudo-random number generators (as opposed to more classical approaches than depend on analytical derivations)
Notation¶
Suggested readings
Computer Age Statistical Inference: Algorithms, Evidence and Data Science by Bradley Efron and Trevor Hastie